Deux algorithmes de tri sont au programme de première en NSI :
- Le tri par sélection
- Le tri par insertion
Nous allons voir désormais un nouvel algorithme de tri qui a une meilleure complexité en temps dans le pire des cas :
- Le tri fusion
Cet algorithme a été inventé par le physicien Von Neumann en 1945.
Pour information, la complexité algorithmique dans le pire des cas de cet algorithme est quasi linéaire : \(O(n \,log(n))\) (On voit aussi la notation sans les parenthèses pour le logarithme : \(O(n \,log \, n)\) ) . Cette complexité est optimale dans le cas des tris par comparaison, c'est-à-dire qu’on ne peut pas faire mieux pour ce type de tri.
Nous allons maintenant expliquer ce que le terme "Diviser pour régner" veut dire dans le cadre de la NSI et ensuite étudier l'algorithme de tri fusion en détail.
1) Diviser pour régner¶
Le tri fusion utilise une technique algorithmique qui s’appelle “diviser pour régner”. Le but principal de cette technique est de réduire la complexité en temps de certains algorithmes.
Cela consiste à :
- Découper le problème initial en sous-problèmes
- Résoudre les sous problèmes (récursivement ou pas)
- Calculer une solution au problème initial à partir des solutions des sous-problèmes
Comme applications on peut citer notamment :
- Recherche dichotomique dans un tableau trié (vu en première)
- Exponentiation rapide
- Multiplication d'entiers (Algorithme de Karatsuba - 1962)
De notre côté nous allons étudier une autre application : le tri fusion.
2) Le tri fusion¶
2.1) Fonctionnement général du tri¶
On se donne une liste de nombres à trier :
On va commencer par diviser continuellement la liste en deux, jusqu’à obtenir des listes qui ne contiennent qu’un seul nombre.
Ensuite, on va pouvoir trier des instances de listes plus petites, une liste qui ne contient qu’un nombre est déjà triée. On combine alors deux éléments de la liste et on les trie, on obtient alors des listes triées qui contiennent au plus deux éléments (si on a un nombre impair d’éléments alors on a une liste qui contient un seul nombre).
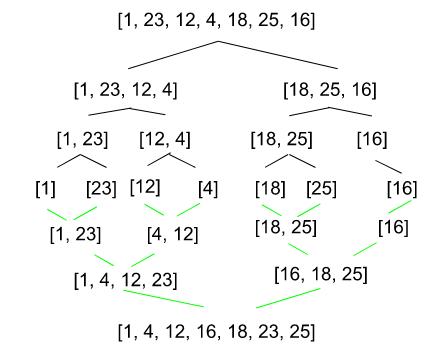
Nous allons étudier et expliquer un pseudo-code que nous implémenterons en Python en TP. On peut séparer ce pseudo-code en deux parties. D'une part nous avons la fusion de deux tableaux triés quelconques et d'autre part les appels récursifs qui permettent de trier l'ensemble du tableau d'origine.
2.2) Fusion de deux tableaux triés¶
Tout d’abord, nous allons utiliser une fonction fusionner qui prend en paramètre deux tableaux triés et qui renvoie un tableau trié qui contient les nombres des deux listes.
Comme dans cette partie extraite de l’arbre ci-dessus :
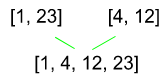
fonction fusionner(tableau_gauche T1, tableau_droite T2) :
T ← tableau vide
i_tableau_gauche ← 0
i_tableau_droite ← 0
Tant que i_tableau_gauche < taille du tableau T1 et i_tableau_droite < taille du tableau T2
Si T1[i_tableau_gauche] < T2[i_tableau_droite]
ajouter T1[i_tableau_gauche] à T
i_tableau_gauche ←i_tableau_gauche + 1
Sinon
ajouter T2[i_tableau_droite] à T
i_tableau_droite ← i_tableau_droite + 1
FinSi
FinTantQue
Si i_tableau_gauche < taille du tableau T1
Tant que i_tableau_gauche < taille du tableau T1
ajouter T1[i_tableau_gauche] à T
i_tableau_gauche ← i_tableau_gauche + 1
FinTantque
Sinon
Tant que i_tableau_droite < taille du tableau T2
ajouter T2[i_tableau_droite] à T
i_tableau_droite ← i_tableau_droite + 1
FinTantque
FinSi
Renvoyer T
Rassurez-vous, ce code est bien plus simple qu’il n’y paraît. On commence par comparer les valeurs dans chacun des deux tableaux (tableau gauche et tableau droit). On insère à chaque fois la plus petite valeur.
Prenons un exemple avec deux tableaux suffisamment petits et un tableau vide qui contiendra les données de tableau_gauche et de tableau_droite triées.
On commence par comparer le premier élément de tableau_gauche et le premier élément de tableau_droite 2 est plus petit que 5, on ajoute donc 2 au tableau.
On compare 4 à 5, 4 est plus petit que 5, donc on ajoute 4 au tableau. Le tableau est alors dans cet état :
On a parcouru tous les éléments de tableau_gauche, cependant il reste les éléments de tableau_droite. La seconde partie de l’algorithme ci-dessous ajoute les valeurs restantes. Dans l’exemple que nous avons donné, il reste des nombres à ajouter dans tableau_droite, mais cette partie de l’algorithme gère les deux cas : soit il reste des nombres dans tableau_gauche, soit il reste des nombres dans tableau_droite.
Si i_tableau_gauche < taille du tableau T1
Tant que i_tableau_gauche < taille du tableau T1
ajouter T1[i_tableau_gauche] à T
i_tableau_gauche ← i_tableau_gauche + 1
FinTantque
Sinon
Tant que i_tableau_droite < taille du tableau T2
ajouter T2[i_tableau_droite] à T
i_tableau_droite ← i_tableau_droite + 1
FinTantque
FinSi
2.3) Appels récursifs et tri du tableau d'origine¶
Enfin on effectue le tri fusion de manière récursive, sur chaque sous-parties du tableau, en coupant le tableau en deux à chaque fois (revoir l’arbre d'exécution si ce n’est pas clair). Le cas d’arrêt correspond au cas où on a un seul élément dans le tableau (qui est donc déjà trié).
fonction tri_fusion(tableau T) :
Si taille du tableau T n’est pas égal à 1 :
milieu ← taille du tableau T / 2
tableau_gauche ← tri_fusion(T[0...milieu - 1])
tableau_droite ← tri_fusion(T[milieu...taille du tableau T - 1])
tableau T ← fusionner(tableau_gauche T1, tableau_droite T2)
Sinon :
Renvoyer tableau T
FinSi
En TP nous allons implémenter cet algorithme et revoir les algorithmes de tri de première.